GDPR Compliance for AI Data Storage
GDPR Compliance for AI Data Storage
Navigating GDPR compliance for AI data storage can be tricky, but here's the gist: if your AI system processes personal data, you need to follow strict rules to avoid massive fines (think €1.2 billion for Meta in 2023). The GDPR demands transparency, security, and accountability at every step, which means balancing the need for loads of data to train AI with strict privacy laws. Here's what you need to know:
- Data Protection Impact Assessments (DPIAs): Mandatory for AI systems to identify risks and map data flows.
- "Right to be Forgotten": A headache when personal data is embedded in AI models, sometimes requiring retraining.
- Cross-Border Data Challenges: Cloud storage often involves data moving across countries, needing Transfer Impact Assessments (TIAs) and encryption.
- Transparency & Accountability: Keep clear records, audit trails, and ensure third-party providers stick to GDPR rules—a task often overseen by a fractional CTO.
Practical steps? Pseudonymise or anonymise data, use encryption (like AES-256), and implement Privacy by Design from the start. Also, work with EU-based servers to avoid legal hassles and make sure every data move is documented. If you're not careful, the fines and reputational risks are no joke. So, start with a DPIA, lock down your data, and keep your processes airtight.
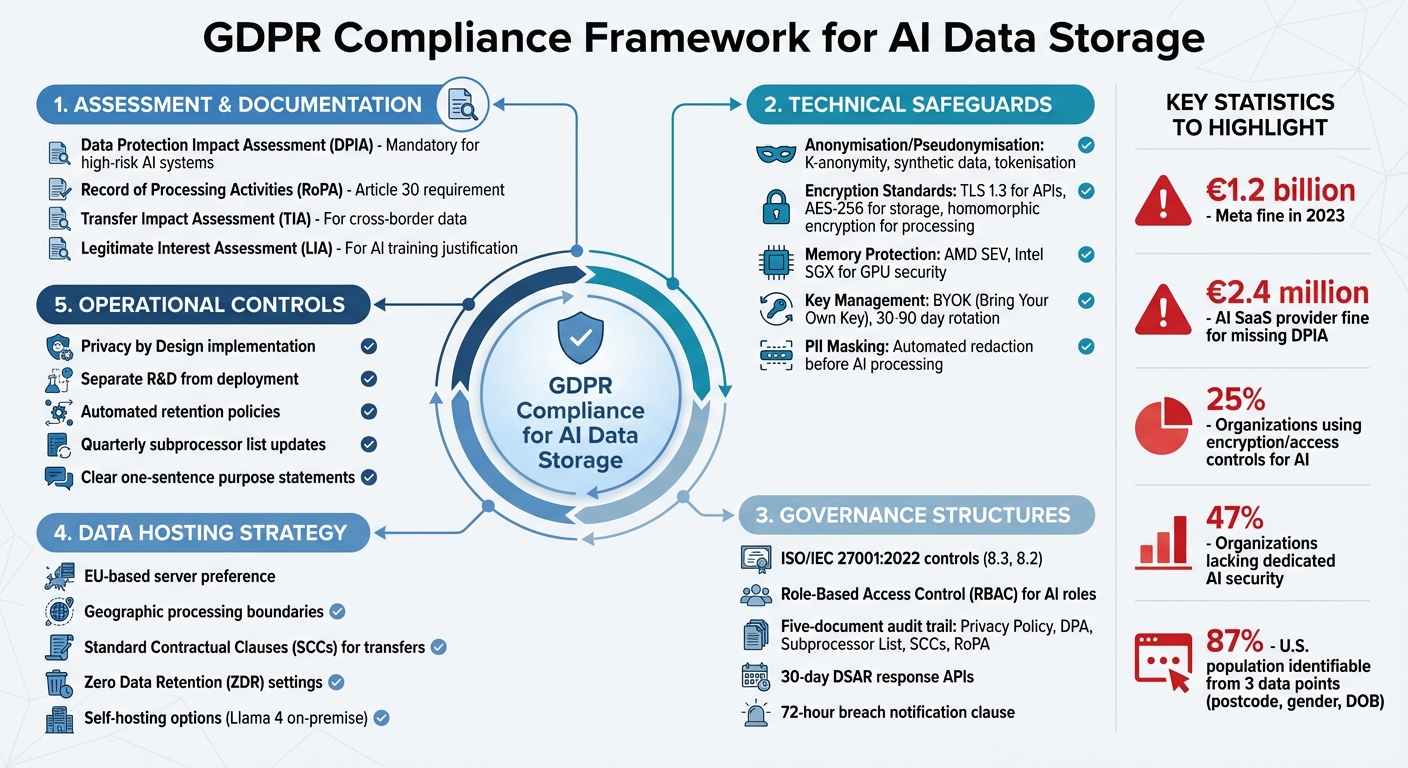
GDPR Compliance Framework for AI Data Storage: 5-Step Implementation Guide
AI Models and GDPR Compliance: Key Insights from the EDPB Opinion
sbb-itb-fe42743
Main Challenges of GDPR Compliance in AI Data Storage
Organisations trying to balance AI data storage with GDPR compliance face three major hurdles. These challenges arise because AI's hunger for data often clashes with the strict rules of data protection laws.
Data Minimisation vs AI Data Needs
Under GDPR, personal data must be "adequate, relevant and limited to what is necessary" (Article 5(1)(c)) [4]. But here’s the catch: AI models thrive on huge datasets - the more data, the better the results. This creates a tricky conflict. To improve accuracy, data scientists often collect a wide range of features, even if they aren’t sure all of them are needed. GDPR, however, flips this mindset. Organisations must decide on the minimum data needed before processing starts [3][4].
Restricting datasets to meet GDPR rules can lead to unintended consequences. For example, reduced data might introduce bias or lower the model’s accuracy. If the model then discriminates against certain groups, it could breach GDPR’s fairness principle [4][7]. So, there’s this constant tug-of-war between needing more data for AI to work well and keeping data usage lean to comply with GDPR.
Then there’s the thorny issue of the Right to be Forgotten (Article 17). Once personal data is used to train a model, it becomes embedded in the model’s structure, making it nearly impossible to remove without retraining the entire system [2][5]. Overfitted models - those that cling too tightly to training data - are particularly risky. They might "remember" specific individuals, leaving them vulnerable to attacks where personal data can be reconstructed from the model’s outputs [4].
Cloud Storage and Cross-Border Compliance
Just because data is hosted in the EU doesn’t mean it’s processed exclusively within EU borders [5]. This is especially tricky in cloud environments where data might move between countries for caching, routing, or other operational reasons. Organisations need to track where their data is processed and accessed, even temporarily.
The Schrems II ruling added another layer of complexity. Now, Transfer Impact Assessments (TIAs) are mandatory to assess whether the destination country’s laws - like US surveillance under FISA 702 - undermine GDPR protections [5][8]. Standard Contractual Clauses (SCCs) remain the go-to mechanism for cross-border transfers, but they need to be backed by "supplementary measures" such as encryption where only the customer holds the keys [5][6].
Big cloud providers are trying to address these concerns. For instance, Azure offers "Data Zones", and OpenAI has "Europe region" projects to ensure data stays within specific boundaries [5]. But organisations can’t just take these claims at face value. Verifying compliance means digging into multiple documents: Privacy Policies, Data Processing Agreements (DPAs), Subprocessor Lists, Data Transfer Mechanism documentation, and Records of Processing Activities (RoPA) [8].
Take Google’s Gemini API as an example. It keeps prompts and outputs for 55 days for abuse monitoring and may temporarily store data in any country where Google operates. This highlights a gap between what’s promised and what actually happens behind the scenes [5].
Proving Accountability and Transparency
AI systems often rely on a mix of third-party code, open-source libraries (like NumPy), and external large language model (LLM) providers. This makes it tough to maintain a clear audit trail across all the moving parts [4][5]. Add to that the "black box" problem - the complexity of machine learning models - and it becomes even harder to explain automated decisions, as required by GDPR’s "Right to an Explanation" [1][6].
Dr. Lena Vogt, a Senior Data Protection Officer at the European Health Tech Alliance, puts it bluntly:
"The most dangerous GDPR claims aren't lies - they're half-truths wrapped in technical jargon. 'Encrypted,' 'anonymised,' 'compliant' - these words become shields when stripped of context. True accountability shows up in deletion logs, subprocessor audit reports, and contracts where penalties for breach are enforceable - not aspirational." [8]
AI training often involves copying and transferring large datasets across various environments, like staging or testing, which might not have the same security measures as production systems [2][4]. When using third-party LLMs, defining roles becomes another headache. If a company uses customer data to improve a global model instead of just delivering a service, they may shift from being a processor to a controller - bringing higher accountability requirements [2][5].
In 2023, these challenges became all too real when the Irish Data Protection Commission fined an AI SaaS provider €2.4 million. Their mistake? Launching a chatbot without conducting a Data Protection Impact Assessment. The chatbot stored sensitive support tickets without a clear lawful basis or retention policy [8]. It’s a stark reminder of how crucial it is to get these details right.
Technical Solutions for GDPR Compliance in AI Data Storage
Tackling GDPR compliance in AI data storage might seem daunting, but there are practical steps you can take to secure personal data without sacrificing AI performance. Right now, only 25% of organisations use encryption or access controls for AI, and 47% lack dedicated AI security measures [10]. Let’s explore some proven methods to address these gaps.
Anonymisation and Pseudonymisation Methods
Pseudonymisation is a handy approach where identifiers like names or email addresses are swapped with artificial codes or tokens. It's reversible, meaning you can re-link the data if you have the key. Under GDPR, pseudonymised data is still considered "personal data", so compliance requirements remain [11][13]. That said, this method reduces risks significantly. For instance, tokenisation is often used in financial systems - credit card numbers can be replaced with random tokens, which fraud detection models can still use to identify patterns without storing sensitive payment details [13].
Anonymisation, on the other hand, takes things a step further by irreversibly removing or altering identifiers so individuals can’t be re-identified. If done properly, anonymised data is exempt from GDPR [11][13]. However, achieving true anonymisation isn’t easy. For example, studies show that 87% of the U.S. population can be uniquely identified using just three pieces of information: postcode, gender, and date of birth [14]. The Article 29 Working Party has warned that many organisations fall short of actual anonymisation [14].
A middle-ground solution is synthetic data generation. This involves training AI on real datasets to create entirely new, statistically representative data that doesn’t contain any actual personal information [11][13]. It’s a great way to retain the data’s utility for training models while sidestepping privacy concerns. Another option is k-anonymity, which ensures that each data record is indistinguishable from at least k-1 others, making it harder to single someone out [13].
To boost security, keep mapping tables or decryption keys stored separately to prevent breaches [12][13].
Encryption and Data Security Measures
Encryption is your first line of defence. For securing communications, TLS 1.3 is the go-to standard for API interactions between application layers and AI services [9][10]. For data stored on servers, AES-256 encryption covers everything from vector databases to backups [10].
In cloud environments, hardware-level memory encryption - like AMD SEV or Intel SGX - can protect data in GPU memory from side-channel attacks while models are processing it [9]. For high-security needs, homomorphic encryption is a game-changer. It allows AI models to perform computations directly on encrypted data without needing to decrypt it, ensuring that sensitive information stays confidential throughout the process [10][13].
To avoid leftover data in memory, clear GPU and system memory after every request [9].
Bring Your Own Key (BYOK) is another effective strategy. It gives organisations control over encryption keys, even when using third-party AI environments. Rotate your keys every 30 to 90 days, and for added security, use certificate pinning and Perfect Forward Secrecy (PFS) cipher suites to block man-in-the-middle attacks [9][10].
Before feeding data into AI systems, use automated scripts to mask or redact PII (Personally Identifiable Information) such as names, emails, or phone numbers. This ensures sensitive information doesn’t enter the pipeline unnecessarily [2]. Implement similar masking or pseudonymisation measures for data leaving production environments [2].
These encryption and security measures are part of a broader strategy where protecting privacy is baked into every stage of AI design.
Privacy by Design Implementation
Beyond technical tools, Privacy by Design ensures GDPR compliance is considered throughout the AI development process [9]. As Dmitry Sverdlik, CEO of Xenoss, puts it:
"Trust starts with data discipline. Privacy is an engineering requirement. Encrypt by default, minimise by design, and keep full audit trails. That's how AI earns its licence to operate." [10]
Start by separating AI systems into distinct layers - Application, Embedding, Retrieval (Vector Database), and Inference. This creates clear boundaries and keeps personal data isolated at each stage [9]. Use dedicated Virtual Private Clouds (VPCs) or VLANs for AI infrastructure, with strict firewall rules to limit access to authorised endpoints [9].
Data minimisation is critical. Review your AI data pipelines and remove fields that aren’t absolutely necessary for model performance before storing the data. For added transparency, provide users with toggles like "Allow data for model improvement", defaulting to opt-out settings [2].
Geographic boundaries simplify compliance too. Using EU-based servers for data storage and processing avoids the legal headaches of cross-border data transfers under GDPR Chapter V [5][9].
Finally, enforce Role-Based Access Control (RBAC) tailored for AI roles. For example, data scientists should only access de-identified training data, not production PII [10]. Automate retention policies to ensure data is deleted or archived according to predefined schedules [10].
Together, these measures lay the groundwork for maintaining GDPR compliance while keeping AI systems secure and efficient.
Operational Approaches for GDPR Compliance in AI Data Storage
When it comes to GDPR compliance, having the right operational processes in place is just as critical as technical safeguards. This means focusing on detailed documentation, solid governance, and carefully considered data hosting strategies.
Documentation and Record-Keeping Requirements
If your AI system handles personal data, a Data Protection Impact Assessment (DPIA) is non-negotiable. Under Article 35, AI systems are automatically deemed "high risk" [1]. A proper DPIA should clearly map out data flows, justify the necessity of AI, and address risks like algorithmic bias or the infamous "hallucinations" [1]. This is where precision in operational controls becomes essential.
You'll also need a Record of Processing Activities (RoPA), as required by Article 30. This should list every data category, purpose, recipient, international transfer, and retention period [8]. For AI training, go a step further: log which datasets were used, the legal basis for their use, and the relevant tenant or user [2]. If you're leaning on "legitimate interest" under Article 6(f) for AI training, you’ll also need a Legitimate Interest Assessment (LIA). This should include a three-part test covering purpose, necessity, and balancing against individual rights [3][5].
For any data stored or processed outside the European Economic Area (EEA), a Transfer Impact Assessment (TIA) is essential to ensure compliance with Schrems II and guarantee "essentially equivalent protection" [5][8]. And don’t forget to hold your AI vendors accountable: require a Data Processing Agreement (DPA) under Article 28. This should cover subprocessor authorisation and include guarantees for data deletion [8].
"The most dangerous GDPR claims aren't lies - they're half-truths wrapped in technical jargon. 'Encrypted,' 'anonymised,' 'compliant' - these words become shields when stripped of context. True accountability shows up in deletion logs, subprocessor audit reports, and contracts where penalties for breach are enforceable - not aspirational." - Dr. Lena Vogt, Senior Data Protection Officer, European Health Tech Alliance [8]
Another key tip? Separate R&D from deployment. These stages often have different lawful bases and risks [3]. For every AI feature, write a clear, one-sentence purpose (e.g., "summarise support tickets") to avoid "purpose drift" - where data ends up being used for things it wasn’t originally meant for [5]. Lastly, publish and update a list of all third-party AI providers and cloud infrastructure partners every quarter, linking directly to their GDPR commitments [8].
Governance and Accountability Structures
With documentation sorted, governance ensures accountability at every level. A solid governance framework should align GDPR requirements with the EU AI Act, creating a unified approach to data protection and system safety [6].
Accountability can be demonstrated through a five-document audit trail: Privacy Policy, Data Processing Agreement (DPA), Subprocessor List, Data Transfer Mechanisms (e.g., SCCs), and Records of Processing Activities (RoPA) [8]. Increasingly, procurement teams are demanding detailed DPAs and audit reports rather than vague "GDPR-ready" assurances [8].
Use ISO/IEC 27001:2022 controls to limit access to sensitive data. For instance, apply controls like 8.3 (Information access restriction) and 8.2 (Privileged access rights) to ensure data scientists only access pseudonymised data on a strict "need-to-know" basis [2]. Policies for Data Masking, Test Data, and Information Security should be in place to guide developers [2].
To handle Data Subject Access Requests (DSARs) within the 30-day deadline, set up API endpoints for data access, export (JSON/CSV), and deletion. These should also work for backups and ML training sets [6]. When working with third-party LLM providers, make sure your DPA explicitly bans them from using your data for their own model training and includes a 72-hour breach notification clause [2][8].
Data Hosting Location Considerations
Once your internal controls are locked down, it’s time to think about where your data physically resides. Don’t just focus on where the data is stored at rest - track where it’s processed and accessed, including by subprocessors. For data transfers outside the EEA, use approved Standard Contractual Clauses (SCCs) and conduct a transfer impact assessment to ensure compliance with Schrems II.
Many providers now offer regionalised hosting options. For example:
- Microsoft Azure offers "DataZone" setups within specific regions.
- AWS Bedrock uses "Geographic cross-Region inference" to keep processing within the EU.
- OpenAI provides a "Europe region" option with "zero data retention."
Make sure your RoPA documents the actual routing and processing geography of AI API calls - don’t rely on marketing labels. For maximum control, consider self-hosting open-source models like Llama 4 on-premise or in private clouds. This eliminates subprocessor risks entirely and gives you complete control over data residency. Where possible, enable Zero Data Retention (ZDR) settings to ensure prompts and outputs aren’t stored by the provider.
Conclusion
Navigating GDPR compliance in AI data storage is all about finding the balance between protecting privacy and maintaining functionality - and, most importantly, earning trust. It’s not an easy task. AI thrives on large datasets, while GDPR pushes for data minimisation. Add cross-border storage complexities and the need for airtight accountability, and it’s clear there’s no shortcut. But with a combination of smart technical safeguards and solid operational practices, these challenges can be tackled head-on.
On the technical side, tools like encryption, pseudonymisation, differential privacy, and federated learning are key players in protecting data throughout the AI lifecycle. Operationally, it’s about dotting the i’s and crossing the t’s: conducting thorough Data Protection Impact Assessments (DPIAs), keeping up-to-date Records of Processing Activities (RoPAs), enforcing clear data retention policies, and securing solid Data Processing Agreements (DPAs) with third-party providers. Together, these measures don’t just tick boxes - they build trust. And as Oleksandr Derechei aptly reminds us:
"GDPR compliance isn't just about avoiding fines. It's about building AI that people actually trust." [6]
The stakes are high. Recent hefty fines show regulators mean business when it comes to non-compliance, making the risks for businesses very real [6].
Looking ahead, the regulatory environment is shifting. The 2025 Digital Omnibus proposal aims to make training AI on pseudonymised data easier, recognising "legitimate interest" as a valid legal basis [6]. This, combined with the alignment of GDPR and the EU AI Act, could pave the way for a future where privacy and innovation go hand in hand. But that future belongs to organisations willing to invest in strong technical systems and disciplined operational practices.
So, where to start? Begin with a DPIA, weave Privacy by Design into your processes, automate your data lifecycle management, and hold your supply chain accountable. These steps aren’t just about compliance - they’re about building AI systems that people can genuinely trust.
FAQs
Do I need a DPIA for my AI system?
Taking the time to carry out a Data Protection Impact Assessment (DPIA) for AI systems isn’t just a box-ticking exercise - it’s a smart move. A DPIA helps you spot and tackle potential data privacy risks early on, keeping your system aligned with GDPR principles like lawfulness, transparency, and data minimisation.
By doing this, you’re not only safeguarding personal data but also ensuring your AI processes information in a way that’s secure and compliant with legal standards. Think of it as a proactive approach to avoid headaches down the line while building trust with users and regulators.
How can I delete someone’s data if it’s in a trained model?
To remove someone’s data from a trained model, you need to tackle the personal data that was part of the training process. This could mean deleting the specific data, retraining the model from scratch, or using privacy-focused methods like differential privacy or federated learning. Adhering to ICO guidelines on data minimisation is key here, as it ensures you're compliant and makes the data harder to trace, which is especially important when managing such requests.
How do I keep AI data processing inside the UK/EU in the cloud?
To keep AI data processing within the UK or EU, it's crucial to choose cloud providers that offer data residency options in these regions. This approach helps you stay in line with GDPR and other local regulations. Beyond that, consider using privacy-preserving techniques such as federated learning or differential privacy. These methods reduce the need to transfer sensitive data, lowering potential risks.
Another important step is conducting regular Data Protection Impact Assessments (DPIAs). These assessments ensure you're compliant and confirm that all data processing is happening strictly within the designated jurisdictions. It's all about staying proactive and keeping data safe while meeting legal requirements.