Bias in AI: Examples and Solutions

Bias in AI: Examples and Solutions
AI bias is a major issue that affects decisions in areas like hiring, healthcare, and criminal justice. It happens when systems trained on flawed or skewed data produce unfair results. For example, facial recognition tech often misidentifies dark-skinned women, and recruitment tools have rejected candidates based on age or gender. These biases aren’t just technical errors - they reflect societal inequalities and can worsen them.
Key takeaways:
- Where bias comes from: Skewed data, poor algorithm design, and human assumptions.
- Examples: Speech recognition systems with higher error rates for Black individuals; healthcare algorithms excluding Black patients from extra care; hiring tools rejecting older candidates.
- How to address it: Test systems for disparities, improve data diversity, adjust algorithms, and involve diverse teams in development.
The solution? Spot the bias early, fix it, and keep monitoring your systems. It’s not just about avoiding legal trouble - it’s about creating systems that work fairly for everyone.
Algorithmic Bias in AI: What It Is and How to Fix It
sbb-itb-fe42743
What AI Bias Is and Why It Matters
AI bias refers to systematic prejudice in the outcomes of machine learning systems, stemming from assumptions made during development or biases in the training data [7]. This isn't just a technical hiccup - it's a reflection of human judgement, historical inequalities, and the processes shaping these systems. When AI makes decisions about job interviews, healthcare priorities, or even the likelihood of reoffending, biased results can have serious, real-world consequences.
The implications are massive. Beyond the ethical obligation to ensure fairness, organisations face technical and legal risks under laws like the EU AI Act and the UK Equality Act. There's also the potential for reputational harm and financial penalties. A stark example: in August 2023, iTutorGroup had to pay around £300,000 to settle claims with the U.S. Equal Employment Opportunity Commission. Their AI recruitment tool had automatically rejected female applicants aged 55 and older, as well as male applicants over 60 - disqualifying more than 200 qualified individuals purely based on age [7].
Where AI Bias Comes From
Bias in AI usually stems from three main areas: training data, algorithm design, and human influences [1][2][6].
Training data is often the biggest issue. If datasets underrepresent certain groups - whether that's based on gender, ethnicity, age, or disability - the AI learns patterns that don't reflect the world accurately [1][6]. Historical data can be particularly problematic, as it often carries the prejudices of the past. For example, if an AI is trained on employment records from a time when women earned significantly less than men, it might perpetuate those wage gaps [3]. Even removing sensitive attributes like race from the data doesn’t always solve the problem, as other factors (like postcode or job title) can act as stand-ins for those attributes, allowing bias to creep back in [1][6].
Algorithm design can also introduce bias. Developers often optimise models for overall accuracy, which can lead to systems that perform well for majority groups but poorly for minorities [6][7]. Some models are so complex that they "memorise" subtle biases in the training data, amplifying existing inequalities [6].
Then there are human factors. Developers might unintentionally bring their own biases - like confirmation bias or cultural assumptions - into the mix [1][7]. Poorly defined problems and subjective labelling during data annotation, especially when teams lack diversity, can make things worse [1][7]. Together, these issues explain why AI bias is such a persistent problem in real-world applications.
How AI Bias Affects People and Organisations
The effects of AI bias ripple through both society and businesses. In healthcare, biased algorithms can lead to unequal treatment or misdiagnoses. For instance, one widely used healthcare risk-prediction tool reduced the number of Black patients identified for extra care by over 50% [5]. Similarly, UnitedHealth's "nH Predict" algorithm prematurely suggested ending post-acute care for elderly patients, such as 91-year-old Gene Lokken. This left his family with a £9,500 monthly bill for rehabilitation that the system overlooked [5].
In recruitment, AI bias can block qualified candidates from opportunities. Amazon, for example, scrapped an AI recruiting tool after it was found penalising CVs that included the word "women's" (like "women's chess club captain"). This happened because the system was trained on hiring data from a male-dominated decade [5][7].
In criminal justice, the COMPAS algorithm used in U.S. courts flagged Black defendants as high-risk for reoffending at a rate of 45%, compared to just 23% for white defendants [3][5].
These examples highlight how widespread AI bias is. A 2024 UNESCO study even found that major language models associate women with "home" and "family" four times more often than men [7]. The Information Commissioner’s Office (ICO) puts it bluntly:
"AI should not distract your decision-makers from addressing the root causes of unfairness that AI systems may detect and replicate" [1].
For businesses, the consequences go far beyond ethics. Legal penalties, public backlash, and poor decisions based on flawed AI can be incredibly costly. Pinpointing where bias originates - and understanding how it manifests - is the first step towards creating fairer, more accountable systems. This foundation is key for tackling bias effectively, as we’ll explore in upcoming sections.
Examples of AI Bias in Action
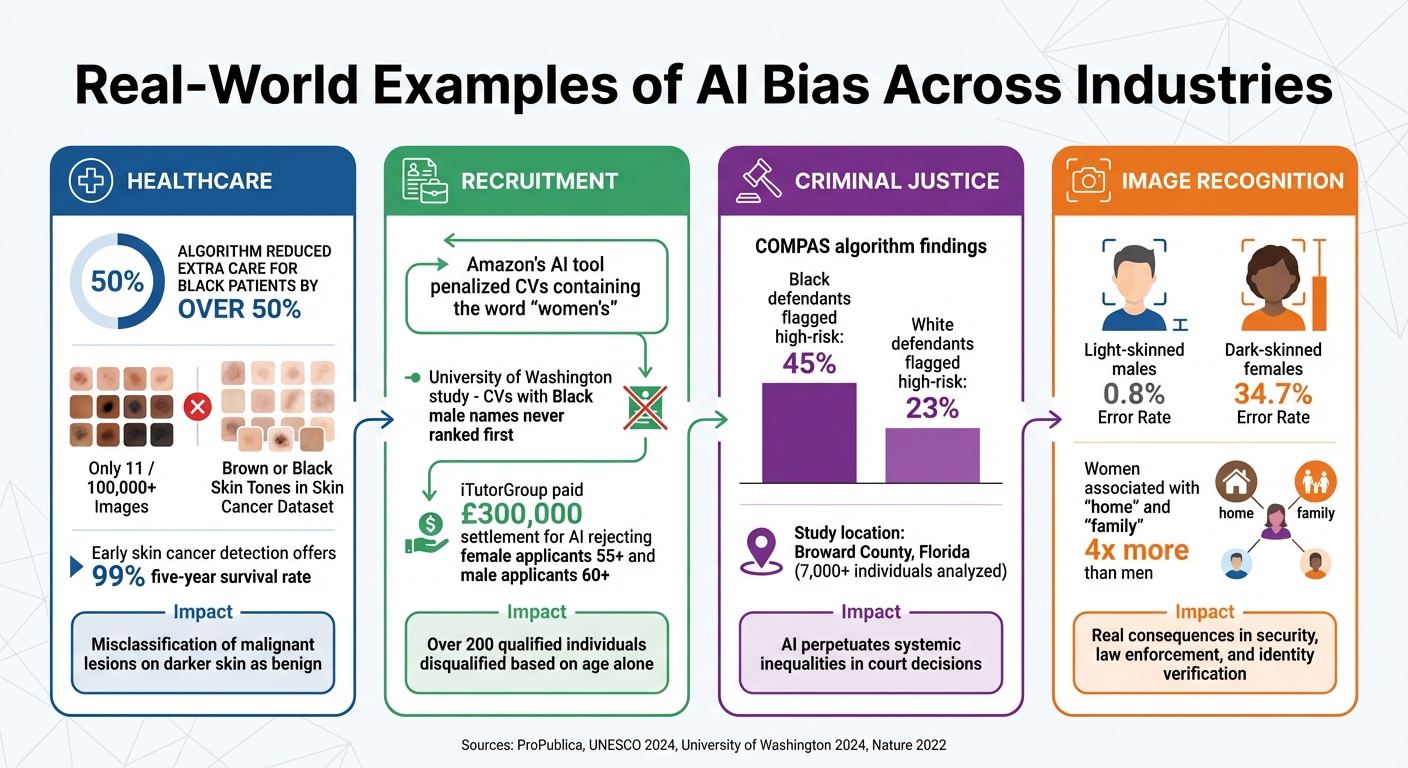
Real-World Examples of AI Bias Across Industries
Understanding how bias emerges and its consequences is crucial, but seeing it in practice truly drives the point home. Let’s explore some documented cases across key sectors where AI bias has had tangible effects.
Healthcare: Unequal Risk Predictions
In healthcare, biased AI systems can have life-altering consequences. One stark example involved an algorithm that reduced extra care for Black patients by over 50%, as previously noted. Another troubling case comes from diagnostic tools for skin conditions. A review of 21 global skin cancer datasets, containing over 100,000 images, revealed that only 11 images explicitly depicted brown or black skin tones [5]. This is a huge problem when you consider that early detection of skin cancer offers a 99% five-year survival rate. If AI systems are trained mostly on images of fair skin, they’re far more likely to misclassify malignant lesions on darker skin as benign [5]. Essentially, the AI can’t recognise what it hasn’t been taught to see.
There’s also evidence of bias in how language models summarise patient notes. Men’s clinical challenges were described as "complex", while women’s were labelled "independent", even when the data was identical [8]. These biases in healthcare reflect similar issues found in recruitment processes.
Recruitment: Discrimination in CV Screening
AI tools used for hiring often inherit and amplify existing prejudices. A 2024 study from the University of Washington demonstrated this clearly. When identical CVs were submitted with names suggesting different ethnic backgrounds, those with Black male names were never ranked first by the AI [7]. Similarly, LinkedIn’s algorithms have been shown to favour male candidates over equally qualified female ones in job recommendations. This occurred even after LinkedIn addressed earlier issues with name-based search biases [5].
A particularly striking example comes from a 2025 lawsuit against Workday. Derek Mobley, a Black job seeker over 40 with a disability, alleged that Workday’s AI screening system systematically discriminated against him and others with similar profiles. A federal judge granted preliminary collective-action certification for the case [5].
These recruitment biases are mirrored in judicial systems, where the stakes are even higher.
Criminal Justice: Racial Bias in Recidivism Predictions
The COMPAS algorithm, widely used in U.S. courts, came under scrutiny in a 2016 ProPublica investigation. It analysed risk scores for over 7,000 individuals arrested in Broward County, Florida, and found that Black defendants were 45% more likely to be incorrectly classified as high-risk compared to 23% for white defendants [5]. This discrepancy highlights how AI can perpetuate systemic inequalities. ProPublica argued that the algorithm violated "equalised odds", whereas its developer, Northpointe (now Equivant), claimed it met "predictive rate parity" [3][5].
Another study, published in Nature in 2022, examined AI recommendations in mental health emergencies. It found that participants were more likely to suggest police involvement for African-American or Muslim individuals than for white individuals in identical scenarios [7].
"The issue is not simply whether an algorithm is biased, but whether the overall decision-making processes are biased." – Centre for Data Ethics and Innovation [4]
This pattern of bias extends to image recognition systems, which have their own set of challenges.
Image Recognition: Misrepresentation and Stereotyping
Facial recognition technology has repeatedly demonstrated glaring disparities in accuracy across demographic groups. A 2018 investigation revealed that error rates for light-skinned males were just 0.8%, while for dark-skinned females, they shot up to 34.7% [5]. These aren’t just technical glitches; they have real-world consequences in areas like security, law enforcement, and identity verification.
Beyond misidentification, biases in AI also reinforce harmful stereotypes. For instance, in 2024, large language models were found to associate women with "home" and "family" four times more often than men [7]. A 2025 study further revealed that these models rated older men higher than older women, even when their qualifications were identical [5]. Such biases risk embedding outdated societal stereotypes into the systems we increasingly rely on every day.
How to Detect Bias in AI Systems
Building on the earlier examples, spotting bias in AI systems is crucial to preventing harm. You can't just assume your AI is neutral - you need to actively test for disparities and evaluate how it performs across different demographic groups. By using structured methods, you can uncover biases during the development and testing phases. These detection methods naturally lead into discussions about how to address the issues they reveal.
Testing for Demographic Parity
Demographic parity testing helps determine whether your AI system's outcomes are distributed fairly across different groups. For instance, decisions like loan approvals, hiring, or risk assessments should occur at similar rates across protected groups unless there’s a valid reason for the difference.
To do this, you can calculate metrics like False Positive Rate (FPR) and True Positive Rate (TPR) for each demographic group. If these metrics show significant differences between groups, it’s a red flag for potential bias. Another useful measure is the Selection Ratio (Rₛₑₗ), which can highlight whether certain groups are over- or under-represented in your data.
Counterfactual fairness is another technique to try. This involves tweaking a protected attribute (like gender or race) while keeping everything else constant. If the model's decision changes, it could indicate that the system is unfairly influenced by that attribute.
"A learning system is regarded as biased if, for some protected attribute A such as race, gender, or disability, at least one widely accepted fairness metric reports a non-zero disparity." – Amar Ahmad, Public Health Research Centre, NYU Abu Dhabi [3]
Interestingly, research shows that improving fairness metrics for groups by 10–15% often results in only a small dip - about 2–5% - in overall model accuracy [10]. So, fairness doesn’t have to come at a huge cost.
Running Third-Party Audits
Even the best internal teams can miss biases, which is why external audits are invaluable. These auditors use adversarial testing to push your system to its limits, identifying scenarios where fairness rules might break down [2][9].
Audits often involve detailed subgroup analyses, looking at accuracy and error rates for specific groups. This approach can reveal disparities that might be hidden in overall performance metrics. For example, a facial recognition system might perform well on average but struggle significantly with certain demographic groups. The "Gender Shades" study famously uncovered error rate gaps of over 30 percentage points between groups [3].
In high-stakes domains like hiring or criminal justice, combining audits with human-in-the-loop validation is critical. Human reviewers can add contextual understanding that purely automated checks might miss, ensuring fairer outcomes before the system goes live [2][9].
Checking Dataset Diversity
Another essential step is evaluating the diversity of your dataset. Even the smartest algorithms can produce biased results if the training data is skewed. Representation bias happens when certain groups are underrepresented in the data, leading to poor performance for those groups [12].
Your training data should reflect actual population distributions [9][6]. Tools like KL divergence can measure how closely your dataset matches the real-world population [3]. If gaps are identified, you can use techniques like re-weighting or oversampling to balance the data [1][2].
It’s also vital to watch out for proxy variables. These are features that, while not explicitly protected attributes, might strongly correlate with them. For instance, a model might not use race directly but could infer it from postcodes or job titles. Simply removing protected attributes isn’t enough if these proxies remain in the dataset [1][6]. Identifying and addressing these variables is key.
Lastly, ensure your data is consistently labelled and updated regularly to stay in step with societal changes [2][6]. Outdated or inconsistent data can introduce new biases or amplify existing ones, so regular checks are non-negotiable.
Solutions for Reducing AI Bias
After identifying bias through testing and audits, the next step is to address it. This involves tackling bias on three fronts: improving datasets, refining algorithms, and establishing strong organisational practices. All three are critical to making headway.
Improving Dataset Quality and Representation
Since AI systems are built on training data, addressing bias starts here. One effective method is balanced data sampling, which involves oversampling underrepresented groups and undersampling overrepresented ones. This helps ensure your model learns from a more balanced dataset [13][1]. When real-world data is lacking for certain groups, synthetic data generation can step in to create artificial data points, helping to represent historically marginalised groups better [13][1].
Another strategy is re-weighting. This means adjusting the importance of specific data points during training so that data from underrepresented groups carries more weight in the model's learning process [2].
It’s also important to watch out for proxy variables. These are data points like postcodes (which might correlate with race) or years of experience (which could correlate with age). Removing explicit labels like "gender" or "ethnicity" isn’t enough if these proxies remain in your model. Addressing these variables directly is essential to avoid indirect discrimination [1][6].
"Fairness is not a goal that algorithms can achieve alone. Therefore, you should take a holistic approach, thinking about fairness across different dimensions and not just within the bounds of your model." – Information Commissioner's Office (ICO) [1]
Once your data is in better shape, the next step is to focus on designing algorithms that actively resist bias.
Designing Algorithms That Resist Bias
Even with a well-balanced dataset, the algorithm itself plays a huge role in mitigating bias. Bias can be tackled at three stages: pre-processing (adjusting data before training), in-processing (modifying how the algorithm learns), and post-processing (tweaking outputs after training) [1][13].
One way to address bias is by incorporating fairness constraints into the algorithm’s optimisation process. This ensures the model meets equity criteria - such as maintaining similar approval rates across demographic groups - while still learning from the data [2][3]. You can also use regularisation techniques, which penalise the model for making discriminatory predictions or showing disparities across groups [13][3].
A more advanced technique is adversarial debiasing. Here, a second "adversarial" network is trained to predict sensitive attributes (like gender or race) from the model’s outputs. The main model then adjusts itself to prevent the adversarial network from succeeding, effectively removing these attributes from its decision-making process [13][3].
Transparency is equally important. Using interpretable models - those that clearly explain their reasoning - makes it easier to identify and fix biased logic. On the other hand, "black box" models might perform well but could hide underlying biases [12][13]. Tools like IBM’s AI Fairness 360 and Microsoft’s Fairlearn offer pre-built fairness metrics and mitigation techniques, saving you from starting from scratch [2].
But technology alone isn’t enough - you also need strong organisational measures to sustain fairness.
Organisational Interventions and Governance
Reducing bias requires more than just technical solutions. You need the right organisational culture and practices. Start by building diverse teams. When people from various backgrounds work on AI projects, they’re more likely to notice biases that homogeneous teams might overlook. This is especially important because statistical models often miss subtle historical or societal inequities [12][13].
Incorporating human-in-the-loop oversight is vital, particularly in high-stakes areas like hiring or criminal justice. Automated systems can lead to "decision-automation bias", where people rely too heavily on AI recommendations without applying their own judgement. Human oversight ensures that nuanced, contextual factors are considered before making final decisions [12][2].
Governance structures should also enforce accountability. For example, the UK GDPR’s Article 25 mandates "data protection by design and by default", requiring organisations to integrate safeguards into AI systems from the start [11]. Conducting Data Protection Impact Assessments (DPIAs) can help identify risks to individuals’ rights, such as potential economic or social disadvantages [11].
"Any processing of personal data using AI that leads to unjust discrimination between people, will violate the fairness principle." – Information Commissioner's Office (ICO) [11]
Transparent documentation is another key measure. Tools like "Datasheets for Datasets" and "Model Cards" provide a clear record of your AI system’s design, training data, and intended use [6][2]. This creates an audit trail and prevents responsibility from being diffused across large teams [11]. Finally, implement continuous monitoring and feedback loops to catch biases that might emerge after deployment. AI systems can influence future data collection, which could reinforce existing disparities if not carefully managed [13][2].
How to Implement Bias Mitigation in Your Organisation
Tackling bias isn’t a one-and-done task - it demands technical action, constant vigilance, and strong technical leadership. Without these, even the best plans can fall flat.
Cross-Functional Collaboration
Let’s face it: no single group can tackle AI bias on its own. Engineers alone can’t carry the load because the expertise needed often spans technical AI know-how, understanding of datasets, and legal compliance. This is why organisations should pull together teams that include AI engineers, data scientists, ethicists, domain experts, and compliance officers. It’s a smart way to handle the shared responsibility of bias mitigation [6][11][12][13].
One useful method is to run collaborative bias self-assessments during every phase of an AI project. These assessments help the team identify potential biases, pinpoint vulnerabilities specific to the project, and document the steps taken to address them [12].
"Bias in AI systems can compound inconspicuously because the necessary expertise around datasets, policy, and rights is not uniformly available among all stakeholders." – Communications of the ACM [6]
Diversity within teams matters too. When people from a range of backgrounds work together, they’re more likely to spot biases that a more uniform group might overlook. For instance, diverse teams are better equipped to recognise "social determinant blindness", where environmental or historical factors that affect marginalised groups are ignored [12].
This collaborative groundwork sets the stage for ongoing checks and improvements.
Continuous Monitoring and Feedback Loops
Interdisciplinary teamwork is just the beginning - regular monitoring is key to keeping things fair over time. AI systems don’t exist in a vacuum; they can influence future data collection and inadvertently reinforce existing inequalities [13]. To stay ahead of this, you should regularly test your model’s performance and track metrics like false positives and negatives across different demographic groups [2][13].
Don’t leave it all to the machines, though. Human oversight is essential, both before and after deployment. Human reviewers can catch biases that automated systems might miss and help counter "automation bias", where people blindly trust AI outputs without applying their own judgement [2][9][12].
Another crucial piece of the puzzle is user feedback. Create mechanisms that allow communities affected by your AI to report any discriminatory patterns they notice. Use this feedback to tweak or retrain your models, keeping fairness as an ongoing priority [9][13].
Leadership Oversight and Transparency
Leadership plays a massive role in embedding fairness into AI practices. A good starting point is adopting "Data Protection by Design and Default", a principle required by UK GDPR’s Article 25. This ensures fairness is baked into every stage of a project, from inception to decommissioning [9][11].
"The more significant the impact your AI system has on individuals... the more attention you should give to these complexities, considering what safeguards are appropriate." – Information Commissioner’s Office (ICO) [11]
Being open about your processes also builds trust. For example, provide "Fairness Explanations" that detail the steps you’ve taken to ensure unbiased decisions. Use tools like "Datasheets for Datasets", which document where your data comes from, its limitations, and how it was collected. This kind of transparency creates a clear audit trail and helps prevent accountability from slipping through the cracks [2][6][11].
Finally, make sure roles and responsibilities are clearly defined. Without clear accountability, it’s easy for things to fall apart. Ethical guidelines and governance frameworks should spell out who’s responsible for what, ensuring both developers and users understand their part in maintaining fairness [2][11][13].
Conclusion
AI bias isn't some far-off issue - it’s already here, influencing people’s lives in areas like healthcare, recruitment, and criminal justice. The impact is hard to ignore. For example, facial recognition systems have been shown to misidentify darker-skinned women over 30% of the time, and mortgage algorithms have charged Black and Latinx borrowers up to 7.7 basis points more than their White counterparts with similar credit profiles [3][5]. These are real-world consequences that demand urgent action.
The first step for organisations is to understand that bias isn’t just a technical flaw. It’s a complex mix of social and technical factors that needs to be tackled throughout the AI lifecycle - from how data is collected to how algorithms are designed and monitored after deployment [3]. Quick fixes won’t cut it, especially when systems end up using proxies to infer sensitive data.
"Fairness is not a goal that algorithms can achieve alone. Therefore, you should take a holistic approach, thinking about fairness across different dimensions and not just within the bounds of your model." – Information Commissioner’s Office (ICO) [1]
Addressing bias effectively requires a broad strategy. This includes assembling cross-functional teams, keeping a close eye on bias over time (often called “bias drift”), and holding leadership accountable. Tools designed to assess fairness can be helpful [2][5], but they’re only part of the solution. Organisations also need to adopt thorough documentation practices, conduct regular audits, and ensure that both datasets and development teams include diverse perspectives.
FAQs
What steps can organisations take to detect and reduce bias in AI systems?
Organisations can tackle bias in AI systems by blending technical approaches with ethical and social insights. One effective step is running regular audits on AI models. These audits can flag biased outcomes, which is especially important in sectors like healthcare, finance, and criminal justice where the stakes are high.
Another critical factor is ensuring that training datasets reflect a wide range of demographic groups. This helps reduce issues like sampling or measurement biases, which can creep in when datasets are too narrow or skewed.
On the technical side, using fairness-aware algorithms and bias mitigation tools can improve both the accuracy and fairness of AI models. But it’s not just about the tech - bringing in a diverse group of stakeholders during development is equally important. This collaboration helps address concerns around ethics, legalities, and social impact.
Finally, following regulatory frameworks, such as the UK’s ICO guidelines on transparency and fairness, is essential for compliance and building trust. By combining thorough testing, diverse data, and open collaboration, organisations can make real progress in reducing bias in AI.
What are the real-world impacts of AI bias across industries?
AI bias can create ripple effects across various sectors, often deepening existing inequalities. Take healthcare, for example. If an algorithm is biased, it might misdiagnose patients or provide unequal access to treatments. This could disproportionately affect specific demographic groups, making existing health disparities even worse.
In the criminal justice system, the stakes are just as high. Biased AI tools used in sentencing or profiling can perpetuate systemic discrimination, undermining public confidence in the fairness of legal processes.
Then there's recruitment. AI-driven hiring systems, if not carefully designed, might unfairly disadvantage groups like older candidates or ethnic minorities. This not only limits career opportunities but also reinforces inequality in the workplace.
These scenarios highlight the need for strong ethical oversight and effective bias mitigation strategies. It's crucial to ensure AI systems are not just efficient but also fair, transparent, and inclusive.
Why is diversity essential in AI development?
Diversity in AI development plays a key role in tackling biases that can creep into systems when teams lack varied perspectives. When AI is built by individuals with similar backgrounds or experiences, it risks unintentionally reinforcing prejudices tied to factors like race, gender, or age. This isn't just a hypothetical issue - real-world examples have shown how biased algorithms can lead to unfair outcomes, from hiring practices to facial recognition errors.
Bringing together people with different viewpoints allows teams to spot and address potential biases early in the process. This makes AI systems fairer, more inclusive, and more in tune with the diverse values of society. In practice, it means creating solutions that don’t just work for one group but are beneficial to a much wider audience.
By prioritising diversity, organisations can create AI tools that people trust and rely on. These tools are not only stronger in their design but also better equipped to serve the needs of a broader range of users, making them more relevant and effective in the real world.